
A five-dollar AI, two ways
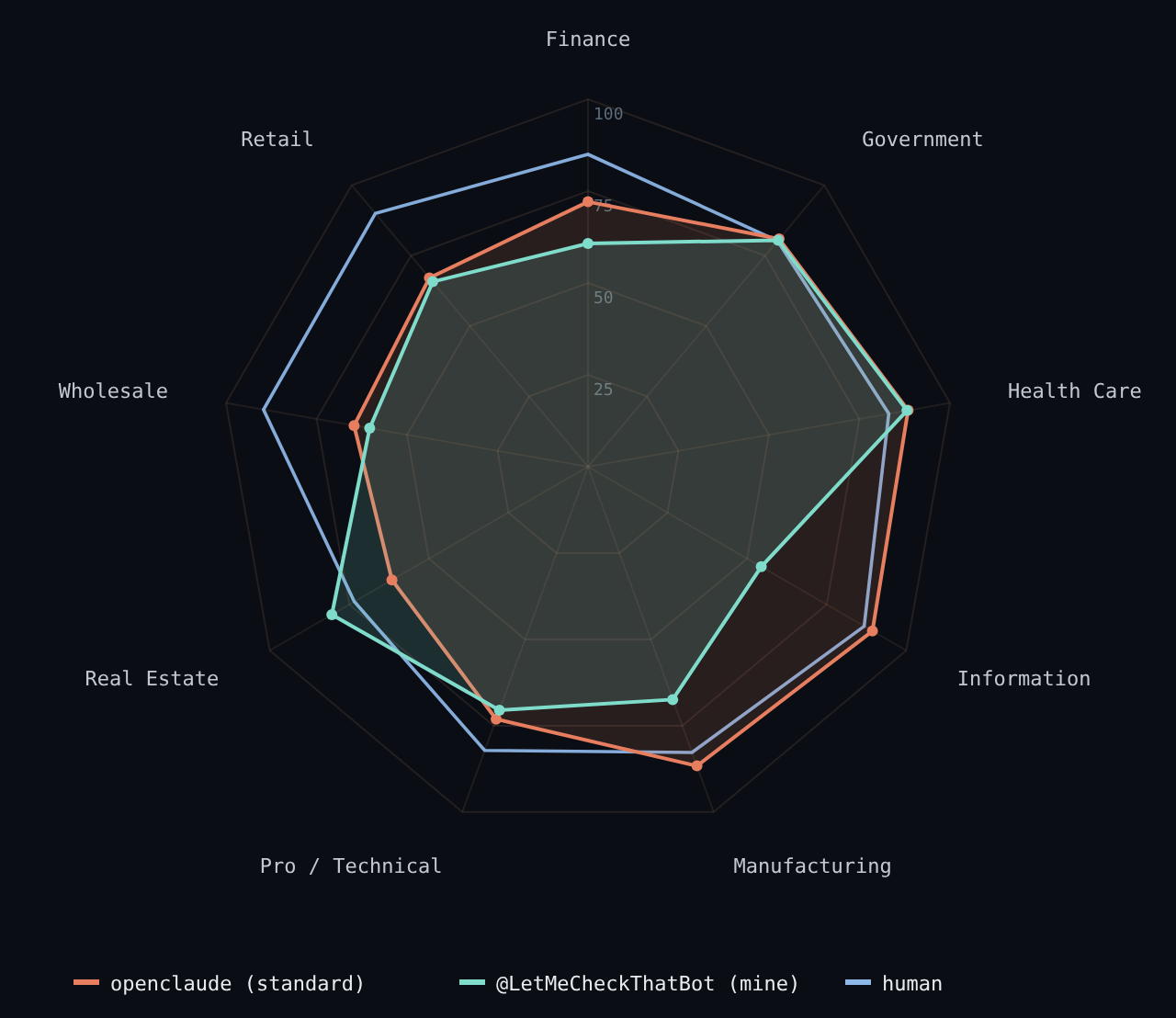
I gave a five-dollar AI model one real task from each of forty-four jobs, a nurse's, a lawyer's, a financial analyst's, graded against each professional's own work. Set up the standard way, it scored 76, eight points off the professionals. Run a second way, through the bot in my group chat, the same model scored 70. I never touched the AI, only the harness around it.
The model is nothing exotic: open-weight, the kind anyone can download and host, though I rented mine through a cheap API for about five dollars a month. It also lives in a group chat with my friends, where it mostly settles arguments and picks restaurants. Same model both times. The six points between those two setups, and the eight between the AI and the pros, are how I will show you what an evaluation actually does.
Where the test comes from
Those numbers came from a test I did not write myself. Last year OpenAI published it, called GDPval. They sat down with professionals across forty-four jobs and wrote down the actual work each job produces, using the government's official list of what every job involves. A nurse fixing how an emergency room hands patients between shifts. A project manager finding a water source for a hydrogen plant. Each task comes with two things I cared about: the professional's own finished work, and a grading rubricthe checklist the work is graded against, a checklist written by the people who do that job.
The whole test is big: 1,320 tasks across those forty-four jobs. OpenAI opened 220 of them for anyone to retest, so I took one task from each job, forty-four in all. A slice of the open set, not the full benchmark. On all of it, OpenAI's own best model matches or beats the experts about half the time. I wanted to see what a five-dollar one would do on the same work.
This kind of test is called an eval, short for evaluation. The idea is plain. Stop arguing about whether an AI seems smart. Hand it the real work, look at what comes back, and grade that. Run that same test across a row of different AIs to rank them and you have a benchmarkan eval reused to rank different AIs.
A score is how much of the checklist the work got right. "Scored 76" means 76 of the 100 points on the professionals' own checklist. This is the number behind the headlines: when a new model comes out and you read it "scored 84," that 84 is exactly this. So: who wrote the checklist, and will they show it to you. Here, they will.
The standard setup, and its name
For the first try, I set the AI up the standard way, the way almost anyone would: a computer, a place to save files, a way to run code, and as much time as it needed.
Engineers have a word for the setup around an AI: the harnessthe setup around the model: its tools, its time, and when it may stop, borrowed from the gear that steers a horse. For an AI it is everything that is not the model: which tools it can reach, how much time it gets, and when it may call itself done. Wire a model into tools in a loop and you get an agenta model wired into tools, working in a loop.
These setups have names. The best-known is Claude Code, Anthropic's coding agent; openclaude is the same idea opened to any model, so I could drop in my five-dollar one; and Artificial Analysis runs a public leaderboard on the same GDPval tasks, scored through a harness it built called Stirrup. Same species: a model, some tools, a loop. My numbers are not from that leaderboard: I ran the model myself, with openclaude as the control, a shell, a way to run code, and all the time it needed.
Three things get lumped together as "the AI": the model, the runner that drives it, and the harness around it. The model never changes here. Watch the harness.
To grade the results, I used a second AI as the judgethe AI that grades the work against the checklist: Claude Sonnet 4.6, made by a different company. It graded the robot's work against the checklists, and the humans' work the same way. Same ruler for both sides.
It scored 76. The humans scored 84. Eight points apart, and on twenty-three of the forty-four jobs it matched or beat the professional outright.
On plenty of jobs it held its own. Given the nurse's task, building a patient-handoff sheet for an emergency room, it tied the professional exactly. Given a software job, it wrote thirty-six files of working code and beat the human.
Then there are the jobs it failed, and they do not look like failure. Asked to build a weekly payroll spreadsheet for a touring Broadway show, it built a beautiful one. Clean tabs, correct formulas, nice formatting. Every pay rate was wrong by about a dollar. It wrote $251.06 where the contract said $252.06, so every paycheck came out wrong, and it scored zero. Asked to schedule move-out inspections for the five tenants leaving an apartment building, it wrote a confident list of twenty-two. It invented the other seventeen, unit numbers and all.
So: a five-dollar AI that does most of the job, and every so often invents seventeen people who do not exist.
My robot runs its own little loop
My group-chat robot works nothing like that standard agent. It is not built on Claude Code, openclaude, Stirrup, or any framework somebody else wrote. Its harness is a little loop I wrote by hand. A few dozen lines. Give the model a handful of tools, let it take up to six steps, stop the moment it sends a message to the chat. I built it to answer a text fast, not to sit a job exam.
So I ran the same five-dollar AI model through my own homemade loop, the one that lives on my phone.
It scored 70. Same model, same tasks, same judge, six points under the standard setup. Nothing about the AI had changed. The only new thing was my harness. So that is where I went looking.
What the evaluation showed me
Here is where the evaluation earned its keep. A vague feeling that the bot was "worse" tells you nothing. A score across forty-four jobs, each with its own checklist, points at exactly what broke. I went back through the jobs where my bot came up short, and none of it was the model. It came down to two settings I had set years ago and forgotten.
The first was time. My robot gives the AI sixty seconds, because a group chat that takes ninety is broken. But a five-dollar AI building a spreadsheet from scratch thinks for about ninety seconds before it writes a single line. The clock ran out mid-thought, every time. A thought that gets cut off looks exactly like an AI with nothing to say.
The second was the finish line. My robot's whole purpose is to send a message. So asked to build a spreadsheet, it would do the work in its head, write a nice description into the chat, and stop. The test grades the actual file. My robot kept handing in a description of the file instead of the file. Zero.
Neither was the model. Both were the harness around it, and the evaluation pointed straight at them. That is the difference between a hunch and a measurement.
Same model, a different number
That is the whole trick of an evaluation. The same five-dollar model, run two ways, scored 76 and 70. On the jobs both setups carried to the finish, the two numbers sat within a point or two of each other. The six points between them were not the model getting dumber. They were the jobs the chat harness never finished: it ran out of clock, or called itself done the moment it sent a message, before it saved the file the test grades.
My group-chat bot is built for speed, to answer a text in seconds, and that same design is what makes it quit early on a long job. The standard agent has all the room in the world, so it finishes more of them. Same model in both. The setup around it is the whole difference.
See all three for yourself
You do not have to take my word for it. I put all forty-four jobs online, side by side: the standard agent, the human professional, and my homemade loop. Each shows the task, all three results, every line of the grading, and the real files you can open, down to the show reel the model cut for a video-editing job. Find the job with your title on it and decide.
Four to start with:
→ See all 44 jobs, three results each, every score
What a score can and cannot tell you
Every score is a measurement taken under conditions. Change the conditions and the number moves. I changed the harness and the same model dropped six points. Hand the same work to a different judge and it shifts again: I had a second AI, from a third company, re-grade a batch, and the two agreed on only 91 of every 100 lines. Let the test age and it can slide a third way, because it is public and a newer model may have trained on it. Same model, same work, three different numbers depending on who measured, how, and when.
So when someone asks the one question everyone asks about an agent, is it any good, the honest answer is that it depends on the eval, the harness, and the judge. Learning to ask which is the whole skill. A score you cannot take apart is just a number someone wants you to believe. This one you can take apart, down to every file and every line of the grading.
Questions people ask
Can a five-dollar AI actually do my job?
No. It can help with pieces of it. On these tests it matched or beat the human on 23 of the 44 tasks, one task per job, and it flopped on plenty of others. It tied a nurse on a handover sheet, then invented seventeen tenants who do not exist on a property task. Replacement is the wrong frame. The useful question is which parts it can take off your plate, and which parts you still have to check yourself.
What is the difference between the model and the harness?
The model is the AI brain. The harness is everything around it: the tools it can reach, how much time it gets, and when it is allowed to stop. Same brain, different harness, and the score moved six points in my test. When a headline credits or blames "the AI," it usually means the whole setup, not just the model.
Why did a polished payroll sheet score a zero?
Because the checklist puts the points on the numbers being right, not on a tidy file. The sheet looked perfect, but every pay rate was about a dollar off, so every paycheck came out wrong. A payroll that pays everyone the wrong amount is a wrong payroll, however clean the formatting. The professionals who wrote the checklist decided correctness is the job, and they are right.
Can you trust an AI to grade an AI?
Not blindly, so I checked it. I ran a second AI judge, from a different company, over the same work. The two agreed on 91 of every 100 line items, and on a few jobs their overall scores still differed by about twelve points. That gap is exactly why I published every line of the grading, so you can see where they agreed and where they did not.
Is one task per job enough to judge a whole profession?
No, and I do not claim it is. I ran one real task from each of forty-four jobs, a slice of OpenAI's larger test, not the whole role. A 100 on one audio task does not mean the model can run an A/V department. It means it handled that one piece of real work. Read every score as a single data point, not a verdict on the job.
This robot only answers a chat
This robot only has to answer a group chat, fast. One little loop, a few tools, and a sixty-second timer I had set wrong for two years without noticing. Penny, the assistant I am building, is a bigger animal. It books my week and pays my invoices, runs on dozens of tools, and "done" means something different for every task. If two forgotten settings could drag a chat bot's score down, imagine what the same kind of mistake hides inside something the size of Penny. So I grade it the same way I graded the robot: give it the real work, score it against what I actually wanted, and read the number knowing exactly what it does and does not mean.