Product build
PagePurger
Three dollars a page to read junk
In medical-legal record review, a person reads every page and bills for it, around three dollars a page. The catch is that a huge share of those pages are duplicates and filler: the same fax sent four times, blank separator sheets, records that have nothing to do with the case. PagePurger reads the stack first and pulls out the pages nobody should be paying to review.
The problem
A single case file can run past eight thousand pages. At three dollars each, the duplicates and the dead weight alone are a serious bill, paid by a human reading things a glance would reject. But you cannot just delete pages on a hunch in a legal record. Every keep-or-drop call has to be defensible later, which is exactly why people read all eight thousand by hand.
The build
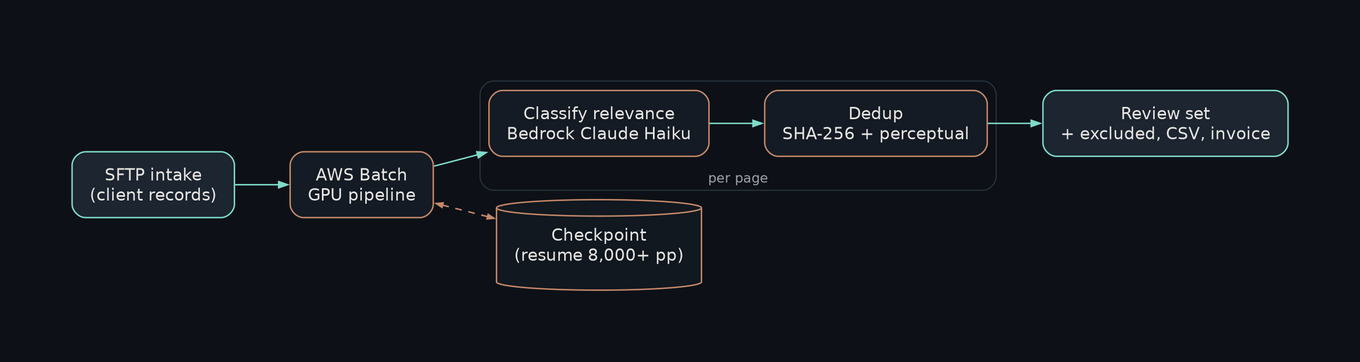
Files arrived over SFTP and the heavy work ran on AWS Batch with GPU machines. A model classified each page for whether it mattered to the case, Claude Haiku on Bedrock or an OpenAI model. It caught duplicates two ways: exact copies by a straight fingerprint of the file, and the near-duplicates, the rescanned page that sits a hair off the original, by perceptual hashing that compares what the page looks like rather than its bytes.
An eight-thousand-page job cannot afford to die at page seven thousand, so it checkpointed as it went and picked back up where it stopped. The output was not one file but a set: the pages to review, the pages pulled out, the watermarked originals, a spreadsheet of every decision, and the invoice. A dashboard showed it happening live.
The outcome
The reviewer opened a stack with the junk already pulled, and a log of why each removed page went, because on a legal record someone can always come back and ask. The models did the routine part. Earning enough trust to drop a page was the part that took real work.